

 Share This Page
Share This Page| Home | | Python | | | | Share This Page |
Latest Version: date
Most recent update to this page:
(double-click any word to see its definition)
If you always have an online connection, if you never need to download podcasts in advance of times without Internet access, this program won't be of much use. But if you're like me, if you sometimes drive or sail long distances, if you sometimes camp in the wild out of range of the Internet, this program may help you — it downloads podcasts when you have an online connection, for use at times when you don't.
Here's a summary:
- PodcastRetriever accepts a list of online RSS feeds you provide, feeds containing audio or video podcasts you're interested in.
- PodcastRetriever downloads the podcasts to local storage and organizes them for viewing/listening.
- PodcastRetriever creates a live Web page that displays all your downloaded podcasts and plays them when you click their titles.
- PodcastRetriever creates special file names for the downloaded podcasts so they appear in a logical order when they're transferred to your MP3 player.
- This means PodcastRetriever helps you create a podcast collection that you can play from a locally generated offline Webpage, as well as download them to an MP3 player for mobile access — all for those times when you're beyond reach of the Internet.
Background
Every summer I cruise Alaska in my boat for about four months, during which time I have no Internet access about 99% of the time. Every winter I make a road trip through the Southwest U.S., with a number of kayak paddles and wilderness hikes along the way. During both these outings I'm sometimes obliged to focus nearly all of my attention on driving my rig or or steering my boat, for many uninterrupted hours. Over the years I began to collect audio podcasts on scientific and technical topics that I'm interested in, to please my ears while my eyes were on duty. To me these podcasts represent a huge improvement over listening to the radio, and I get to catch up on topics that I would be reading about if only I could read and drive at once.
But in those early days of podcasts, it seemed like each online podcast source had a different way to organize and list their media. As a result I found myself writing a different program for each source, such that my code to acquire podcasts became a nightmarish mess, something no self-respecting programmer is happy about. Worse, every few months one or another of the sites would reorganize their Web pages, so I was obliged to rewrite my acquisition code.
But recently there's been a major and beneficial change to online podcast sources. It seems the advantages of having a single way to describe online media has dawned on nearly everyone, and all the podcast sources I depend on have switched over to a standard method for describing their content — basically, an XML-formatted document (an "RSS Feed") that lists available podcasts with download links, titles and descriptions (here's an example).
This change means I can write one acquisition program and submit a long list of sites to it, with a reasonable expectation that the program will be able to download content exactly the same way from each site. After substantial development effort this all now works as planned, and my podcast acquisition code shrank dramatically in size, something nearly unheard of in the software business.
For the new program, I only need to locate an RSS feed URL and title for each podcast source, enter these into a table of values in my program, and run the program. PodcastRetriever then creates a storage subdirectory for each source (very useful for MP3 players) and fills it with podcasts that meet a date criterion that I also set (I usually limit downloads to the most recent calendar year, but this is an easily changed user option).
For my MP3 player, which I listen to when I'm paddling my kayak or hiking in the wild, I load it with a number of the podcast subdirectories created by PodcastRetriever. Most MP3 players understand the idea that a subdirectory equals a source or category, and because I've renamed the podcasts to include their dates, the player lists the podcasts in the order of their release date.
CustomizationThis program runs equally well on Windows and Linux, but both installations require the user to have some knowledge of computers — it's not an automatic installation on either platform, but it's easy. Some file editing is required, moving files from place to place, nothing very advanced.
For both Windows and Linux, the host machine must have Python 3 installed. Here are download links:
- Windows: ( 32 bit | 64 bit )
- Linux: Open a terminal emulator, and type ( Fedora: "sudo yum install python3" | Debian/Ubuntu/Mint: "sudo apt-get install python3" ).
- The primary PodcastRetriever download is this zip file: PodcastRetriever.zip (this program is released under the GPL). Click the link and acquire the download. Then:
For Windows:
- Unzip the ZIP archive and move the directory it contains to any convenient location, for example your user directory
c:\users\(user name)\PodcastRetriever.- While browsing the directory's contents with a file browser, right-click the
PodcastRetriever.pyfile and select "Create Shortcut".- Right-click the resulting shortcut (which should be named PodcastRetriever.py - Shortcut.lnk) and choose "Properties".
- In the "Target" entry, scroll to the right, past the name of the program, and enter some options (all on one line):
- --year=(current year)
- --month=(current month)
- --day=(choose a day about a week ago)
- --keep
- Now save your changes, then click the shortcut. (The idea of the above entries is to download just a few podcasts, as a test of the installation.)
For Linux:
- Unzip the ZIP archive and move the directory it contains to any convenient location, example your user directory:
/home/(user name)/PodcastRetriever.- While browsing the directory's contents with a file browser, right-click the
PodcastRetriever.shfile and select "Open With ... Text Editor".- On the line that includes the words "# put your requirements here", but just to the right of
PodcastRetriever.py, enter these options (all on one line):
- --year=(current year)
- --month=(current month)
- --day=(choose a day about a week ago)
- --keep
- Now save your changes, exit the editor, and click the shell script
PodcastRetriever.sh. (The idea of the above entries is to download just a few podcasts, as a test of the installation.)- At this point, if an error occurs, it's most likely because the default terminal emulator I've included in the script (xterm) isn't installed on your system. To solve this problem, change the entry for "terminal" in "PodcastRetriever.sh" to one of the other choices — for example, you might want to try "gnome-terminal" instead.
- For both Windows and Linux, if you have followed all the steps correctly, the program will visit the sites in the default podcast source list and, with any luck, download a few podcasts. If the program begins downloading a huge list of podcasts, cancel the running process and review your editing using the above instructions — you want a beginning date just a few days before the date you run the test.
- After the program is done downloading podcasts, there will be some new subdirectories in the PodcastRetriever directory. Here is a screenshot of the result after an example download:
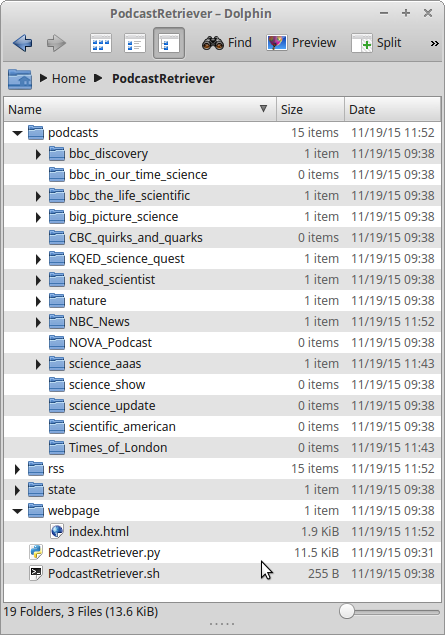
Figure 1: Directory tree after example download
- In my example run, I chose a period of only a few days from the present date, so a handful of podcasts were downloaded, just enough for a test of the webpage that PodcastRetriever generates.
- Now open the subdirectory "webpage" (see Figure 1 above) and click the generated webpage file "index.html." If all has gone according to plan, your browser will open and display a page looking more or less like this:

Figure 2: Webpage display (click for full size)
- If you click one of the titles in the Webpage, the podcast should play (most modern browsers support the playing of MP3 files as well as videos).
- If you hover over one of the podcast titles, you should see a descriptive text as shown in Figure 2. This helps you locate content you may find interesting.
- Remember, this is just a test of the installation — you may not care to listen to a bunch of scientists discussing their work. In the next section we show how to acquire podcasts of your choosing.
MP3 Player DownloadsIn this section I explain how to choose podcast sources that meet your personal needs and tastes.
The podcast source list is located in a configuration file located at "state/resources.txt", which you are free to edit with your choices. But first you need to locate RSS feed Internet addresses (also known as "URLs") for your favorite podcast sources. Here's an example:
- Open a browser, go to Google, and enter "NBC News" and "podcasts", quoted separately, as your search string. Press Enter.
- The first result should be the NBC News podcast page.
- Scroll to the bottom of the page and locate "Nightly News audio podcast" at the lower left. Right-click a link marked "Other podcast client (RSS)", and choose "Copy Link Address" (your browser may use different words for the same function). Your system clipboard should now contain "http://podcastfeeds.nbcnews.com/audio/podcast/MSNBC-Nightly.xml".
- Locate, and open in your favorite text editor, a file named "resources.txt" in the "state" subdirectory. By default the file should contain this:
# paired XML data file URLs and user-chosen names for podcasts http://rss.acast.com/naked_scientists_podcast/,naked_scientist http://downloads.bbc.co.uk/podcasts/radio4/tls/rss.xml,bbc_the_life_scientific http://downloads.bbc.co.uk/podcasts/worldservice/discovery/rss.xml,bbc_discovery http://downloads.bbc.co.uk/podcasts/radio4/iots/rss.xml,bbc_in_our_time_science http://www.abc.net.au/radionational/feed/2885480/podcast.xml,science_show http://www.nytimes.com/services/xml/rss/nyt/podcasts/scienceupdate.xml,science_update http://feeds.pbs.org/pbs/wgbh/nova-audio,NOVA_Podcast http://arewealone.libsyn.com/rss,big_picture_science http://www.cbc.ca/podcasting/includes/quirksaio.xml,CBC_quirks_and_quarks http://www.kqed.org/rss/questaudio.xml,KQED_science_quest http://www.sciencemag.org/rss/podcast.xml,science_aaas http://feeds.nature.com/nature/podcast/current?format=xml,nature http://rss.sciam.com/sciam/science-talk,scientific_american- If you prefer, you can delete all the science-related podcast sources, or you can "comment them out" so they can be revived later (this is an optional step):
# paired XML data file URLs and user-chosen names for podcasts # http://rss.acast.com/naked_scientists_podcast/,naked_scientist # http://downloads.bbc.co.uk/podcasts/radio4/tls/rss.xml,bbc_the_life_scientific # http://downloads.bbc.co.uk/podcasts/worldservice/discovery/rss.xml,bbc_discovery # http://downloads.bbc.co.uk/podcasts/radio4/iots/rss.xml,bbc_in_our_time_science # http://www.abc.net.au/radionational/feed/2885480/podcast.xml,science_show # http://www.nytimes.com/services/xml/rss/nyt/podcasts/scienceupdate.xml,science_update # http://feeds.pbs.org/pbs/wgbh/nova-audio,NOVA_Podcast # http://arewealone.libsyn.com/rss,big_picture_science # http://www.cbc.ca/podcasting/includes/quirksaio.xml,CBC_quirks_and_quarks # http://www.kqed.org/rss/questaudio.xml,KQED_science_quest # http://www.sciencemag.org/rss/podcast.xml,science_aaas # http://feeds.nature.com/nature/podcast/current?format=xml,nature # http://rss.sciam.com/sciam/science-talk,scientific_american(Placing a '#' hashmark to the left of an entry deactivates it, but preserves it so it can be reactivated later.)
- Now let's add a new entry for the NBC News podcast feed — the location of the entry doesn't matter:
# paired XML data file URLs and user-chosen names for podcasts http://podcastfeeds.nbcnews.com/audio/podcast/MSNBC-Nightly.xml,NBC_News- Now save your edited file "state/resources.txt" and run the PodcastRetriever program. Click on your defined shortcut (Windows) or the PodcastRetriever.sh shell script (Linux), each of which by now should have a narrow date range defined as explained above.
- If everything has been set up correctly, you should see something like this:
Checking online "NBC_News" resource ...
Downloading podcast "NBC_Nightly_News_audio_11_18_2015_213043" ... 100%
Finished, downloaded 1 new podcasts.
- Under the "podcasts" subdirectory, a new subdirectory should be present, named "NBC_News", containing the downloaded podcast.
- For those with large systems and plenty of storage space, PodcastRetriever can retrieve video as well as audio "podcasts". To test this ability, enter this video "podcast" source into the "state/resources.txt" data file:
# paired XML data file URLs and user-chosen names for podcasts http://www.pbs.org/wgbh/nova/rss/nova-vodcast-pb.xml,NOVA_video_podcast- If nothing is downloaded in this example, try changing the earliest acceptable date — some sites don't have recent content.
- As before, you should be able to open the generated Web page located in the "webpage" subdirectory, view it with your system browser, and click on any podcast you're inerested in hearing/seeing.
- One possible error can come up if the RSS feed you chose isn't either an audio or video RSS feed, but some unrelated kind of feed. In this case, PodcastRetriever won't be able to read it or download any content, and will instead print error messages.
Some DetailsIn modern times this is a very simple task — just plug your MP3 player into your computer, at which point it should appear as a normal storage device. Then copy some of the podcast directories generated by PodcastRetriever from your desktop/laptop machine to the MP3 player. Here's a typical setup, with the source filesystem at the left and the MP3 player's filesystem at the right:


It's a simple matter of dragging and dropping files/directories from the left to the right and specifying "Copy".
File Dates
PodcastRetriever gives the podcasts names that begin with the original podcast's release date, and redates the files with their release date, so most players will list the podcasts by release date with no special effort on the user's part. This is ideal for podcasts that need to be organized by date.
Copyright IssuesThe PodcastRetriever program accepts command-line arguments to set some of its operating parameters. Here's a typical terminal emulator session on Linux:
$ PodcastRetriever.py --help usage: PodcastRetriever.py [-h] [-p PODCASTS] [-w WEBPAGE] [-r RSS] [-s STATE] [-y YEAR] [-m MONTH] [-d DAY] [-k] optional arguments: -h, --help show this help message and exit -p PODCASTS, --podcasts PODCASTS Podcast storage directory, default "podcasts" -w WEBPAGE, --webpage WEBPAGE Web page directory, default "webpage" -r RSS, --rss RSS RSS feeds storage directory, default "rss" -s STATE, --state STATE Program state storage directory, default "state" -y YEAR, --year YEAR Earliest year, default 2014 -m MONTH, --month MONTH Earliest month, default 1 -d DAY, --day DAY Earliest day, default 1 -k, --keep Keep window open after retrieval is finishedNormally you place your option choices in your defined shortcut (Windows) or in PodcastRetriever.sh (Linux), as explained above. Here are the options and their meanings:
- --help Show the above help display.
- --podcasts Define a storage directory for your podcasts if you don't want the default location of "podcasts". The provided location can be anywhere on the local system.
- --webpage Define the webpage directory if you prefer not to use the default of "webpage". PodcastRetriever will generate a web page in the directory you choose.
- --rss Define an RSS feed file directory other than the default of "rss".
- --state Define a program state directory to contain the "ever_downloaded.txt" and "resources.txt" files, default "state".
- --year, --month and --day Define a date that limits podcast downloads to dates equal to or greater than that date. For example, if you enter --year=2014 --month=6 --day=15, PodcastRetriever will reject podcasts with release dates before that date. This is a way to avoid downloading too many podcasts from sites that have multi-year archives. With no date entries, PodcastRetriever defaults to January 1 of the prior year (i.e. 1-1-2014 for any date in 2015).
- --keep This option keeps the terminal window open after PodcastRetriever is done downloading podcasts, so you can review what it's done and examine any error messages. By default PodcastRetriever closes the window when it's done.
Ever Downloaded
From one run to the next, PodcastRetriever keeps track of its past actions in a file named "ever_downloaded.txt", located in the "state" subdirectory. This is an important feature — it prevents the re-downloading of podcasts you've downloaded, listened to, and deleted. But there's one problem with this program state memory — if you inadvertently delete a podcast you meant to keep, PodcastRetriever won't re-download it unless you delete its name from "state/ever_downloaded.txt". This has the effect of erasing the program's memory of the podcast and allows it to be downloaded again.
Moving your Podcast Collection
If you have downloaded some podcasts, then decide to move the entire collection from its default location, be sure to tell PodcastRetriever about your change, otherwise the program won't be able to list the podcasts in its generated Web page. In detail:
Let's say you move your entire podcast collection from (typical Windows location) \users\(user name)\PodcastRetriever\podcasts to \MyPodcasts. To do this seamlessly without causing any problems, be sure to add this argument to your program shortcut/shell script:--podcasts=\MyPodcastsRemember this action if you decide to move your collection — if the PodcastRetriever generated Web page is suddenly and inexplicably blank, this is the most likely reason.
Version HistoryAs to my program, there shouldn't be any copyright issues, since like most of my programs it's released under the GPL, which means anyone can use it to his heart's content, even change it for some new purpose, so long as he keeps my copyright notice in the program and doesn't claim it as his own. But as to the downloaded podcasts, their copyright remains with its creators, and downloaders have only borrowed the content for personal use.
This means that, even though my program makes it easy to download a great deal of copyrighted content, the rights to that content are limited: the content cannot be uploaded to another Internet site, or repackaged for distribution in some other form, or modified in a way that conceals its true place of origin.
In this way the downloaded podcasts have the same standing as music MP3s — the recipient is free to use the content for private personal enjoyment, period. I have added this note to instruct those who may be too young and inexperienced to understand this issue from the perspective of someone who has struggled to create worthwhile content with the expectation that they will receive due recognition for their creative efforts.
- 2019.10.13 Version 1.3. Added code to improve reliability of Web RSS page downloads.
- 2017.08.14 Version 1.2. Added some code to clean up podcast titles for more naming uniformity.
- 2015.11.28 Version 1.1. Moved the URL list to a separate data file located at state/resources.txt, fixed a few bugs.
- 2015.11.18 Version 1.0. Initial Public Release.
| Home | | Python | | | | Share This Page |
